
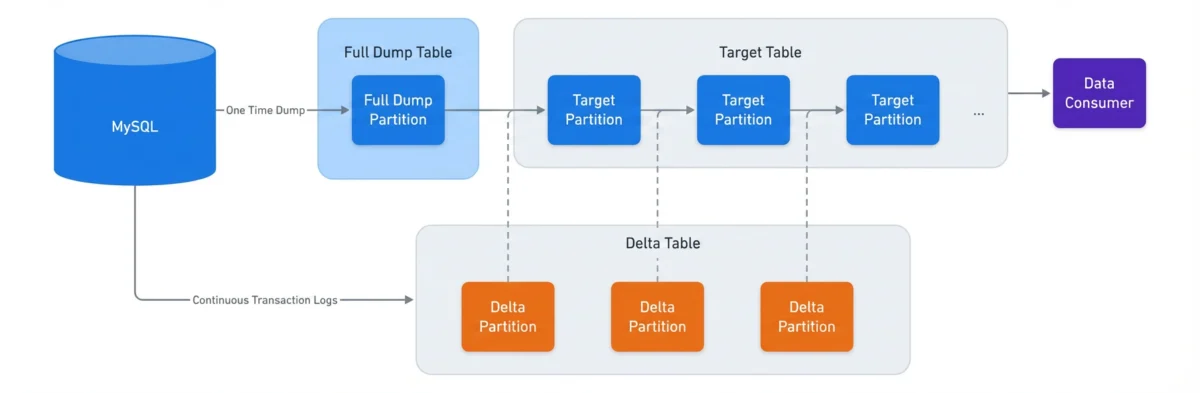
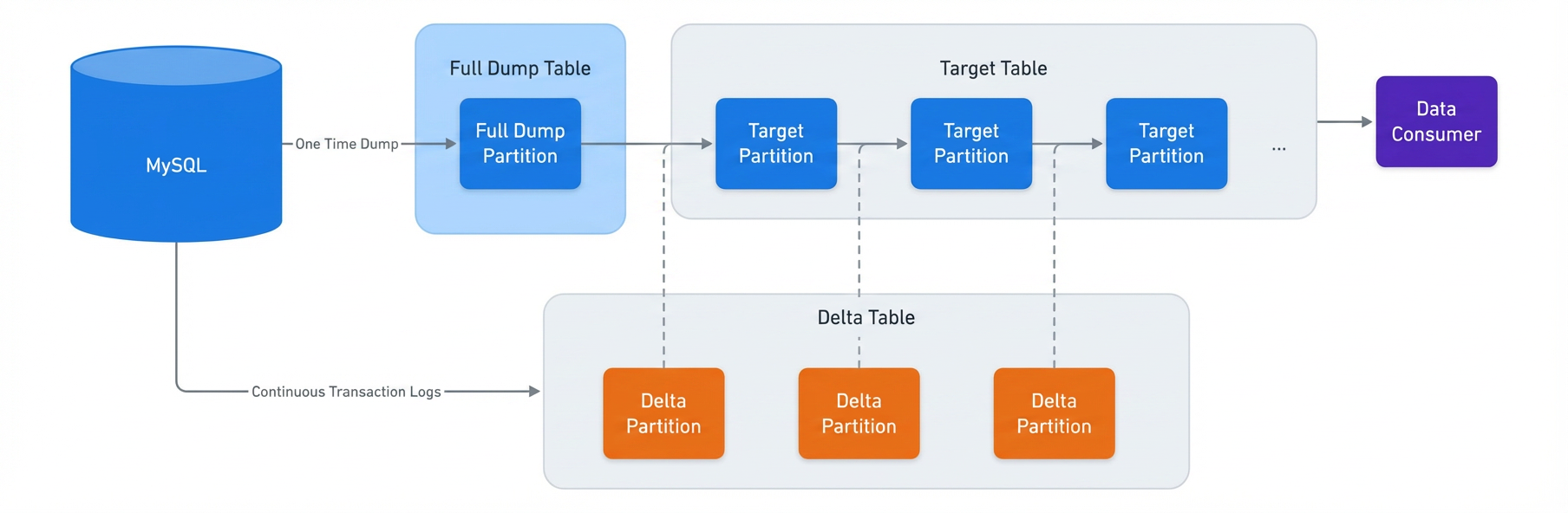
Meta, the parent company of Facebook, Instagram, and WhatsApp, operates one of the most sophisticated data environments in existence. At the heart of this ecosystem is a massive social graph—a complex web of connections between billions of users, interactions, and content pieces—powered by one of the world’s largest MySQL deployments. To turn this raw transactional data into actionable insights, Meta relies on a high-velocity data ingestion system that scrapes several petabytes of information daily into its data warehouse.
This infrastructure is the lifeblood of the company, fueling everything from real-time decision-making and business reporting to the training of massive machine learning models and future product development. However, as Meta’s global footprint expanded, the legacy ingestion system began to buckle under the strain. In a recent engineering breakthrough, Meta successfully migrated its entire data ingestion workload to a modernized, self-managed architecture. This article explores the technical journey, the rigorous migration strategy, and the implications of this monumental shift.
The Migration Challenge: When Scale Becomes a Bottleneck
For years, Meta relied on a system of customer-owned pipelines. While these functioned effectively during the company’s earlier growth stages, they became increasingly brittle as data volume and velocity requirements surged. The legacy architecture was essentially a collection of siloed pipelines, which grew increasingly difficult to manage as the company’s data needs hit the "hyperscale" threshold.
As operations grew, the system began to exhibit signs of instability, failing to meet increasingly stringent data-landing time requirements. Engineers faced a dual-front war: they needed to build a more efficient, self-managed service that could handle massive throughput while simultaneously migrating tens of thousands of existing jobs without causing a single minute of downtime for data-dependent teams. The challenge was not just technical—it was operational. How does one replace the engine of a jet while it is mid-flight?
Chronology of a Systematic Transformation
To ensure the integrity of the petabytes of data being processed, Meta’s engineering team adopted a phased, highly controlled migration lifecycle. The strategy was designed to prioritize data correctness and system reliability above raw speed.

Phase 1: The Shadow Phase
The migration began with a "Shadow Phase." In this pre-production environment, engineers created "shadow jobs" that mirrored actual production workloads. These jobs consumed the same source data as their production counterparts but directed their output to isolated "shadow tables." This provided a sandbox to observe how the new system behaved under real-world pressure without impacting production data. By continuously monitoring row counts and checksums between the legacy and new outputs, the team could identify and rectify discrepancies in real time.
Phase 2: The Reverse Shadow Phase
Once the shadow jobs proved reliable, the team moved to the "Reverse Shadow Phase." In this bold step, the new system took over the primary production write path, while the legacy system was relegated to the shadow role. This approach offered two critical advantages: it provided ongoing validation against the legacy system’s output and created an instantaneous rollback mechanism. If the new system failed, engineers could revert to the legacy system without needing to reconfigure or redeploy it, as it was still running in the background.
Phase 3: Migration Cleanup
Only after a sustained period of error-free operation in the reverse shadow phase were the legacy jobs finally deprecated. This methodical, three-tier approach allowed Meta to systematically dismantle the old architecture, one batch at a time, ensuring that data quality never faltered throughout the transition.
Supporting Data: Custom Tooling for Quality Assurance
The sheer scale of the migration necessitated the development of sophisticated, automated debugging tools. Meta’s engineers built a proprietary data quality analysis tool that functioned as an automated auditor for every job.
For each shadow table partition created, the tool performed a deep-dive verification against the corresponding production table partition. It checked row counts and checksums, logging any mismatches to Scuba, Meta’s internal, real-time data management and analysis platform.

Every hour, the tool analyzed the logs from Scuba to pinpoint specific rows causing discrepancies. This automated feedback loop allowed engineers to distinguish between known, manageable edge cases and critical bugs that required immediate intervention. This tool proved so successful that it has been integrated into the permanent release validation process, serving as a lasting legacy of the migration project.
CDC and the Risk of Data Propagation
A significant technical hurdle was the use of Change Data Capture (CDC). Because the system uses existing landed data to generate new data, any corruption in an early stage would cascade through the entire pipeline. To mitigate this, Meta implemented a "Bad Data" flag within the metadata. If a quality issue was detected, the system would immediately halt the propagation of that partition. If the issue occurred in a target partition, the system would intelligently revert to a previous, clean partition and merge it with fresh deltas, effectively "healing" the data stream before the error could reach downstream consumers.
Official Responses and Engineering Philosophy
Meta’s leadership has emphasized that this transition was not merely a replacement of hardware, but a fundamental shift in how the company approaches data infrastructure. By moving from customer-owned, siloed pipelines to a unified, self-managed warehouse service, the company has lowered the "tax" on its internal engineering teams.
"The goal was to build a system that remains efficient at hyperscale while reducing the cognitive and operational load on our developers," an engineering spokesperson noted. By automating the migration lifecycle and creating centralized dashboards for job tracking, the company effectively democratized the ability to manage complex data flows, allowing product teams to focus on features rather than infrastructure maintenance.
Implications: A Blueprint for Hyperscale Infrastructure
The completion of this migration—transitioning 100% of the workload—marks a significant milestone in Meta’s engineering history. The implications of this project are threefold:
- Reliability at Scale: By utilizing the "Reverse Shadow" technique and automated checksum validation, Meta has established a new standard for how large organizations can perform "zero-downtime" migrations on critical infrastructure.
- Resource Optimization: The project taught the team the value of batching. By carefully selecting jobs based on priority and resource usage, and by avoiding the creation of shadow jobs for known-buggy processes, the team saved massive amounts of compute power that would have otherwise been wasted on unnecessary "full dumps" of source databases.
- Future-Proofing: The move to a self-managed, unified service means that Meta’s data infrastructure is no longer a collection of disparate parts, but a cohesive, scalable unit. This provides the agility required to support future AI workloads and real-time product features that were previously constrained by the limitations of the legacy pipelines.
As Meta continues to push the boundaries of social graph analysis and AI-driven content delivery, this new ingestion architecture serves as a robust, resilient foundation. The lessons learned during this migration—particularly the focus on automated, verifiable, and reversible deployment phases—will likely serve as a blueprint for other tech giants navigating the complexities of petabyte-scale data engineering.
The successful decommissioning of the legacy system is not just an end; it is the beginning of a more efficient, data-dense era for Meta’s engineering teams, ensuring that the company’s massive MySQL deployments remain a source of strength rather than a point of failure.








