
In the rapidly evolving landscape of software development, artificial intelligence has transitioned from a novel assistant to a core component of the engineering workflow. While developers frequently use AI for code generation and debugging, GitHub is pushing the boundaries of this technology by deploying an experimental general-purpose accessibility agent. This initiative marks a significant shift in how large-scale platforms manage digital inclusion, moving from purely reactive, manual auditing to a proactive, agent-driven model that integrates accessibility directly into the pull request (PR) lifecycle.
Main Facts: The Agent-Based Approach to A11y
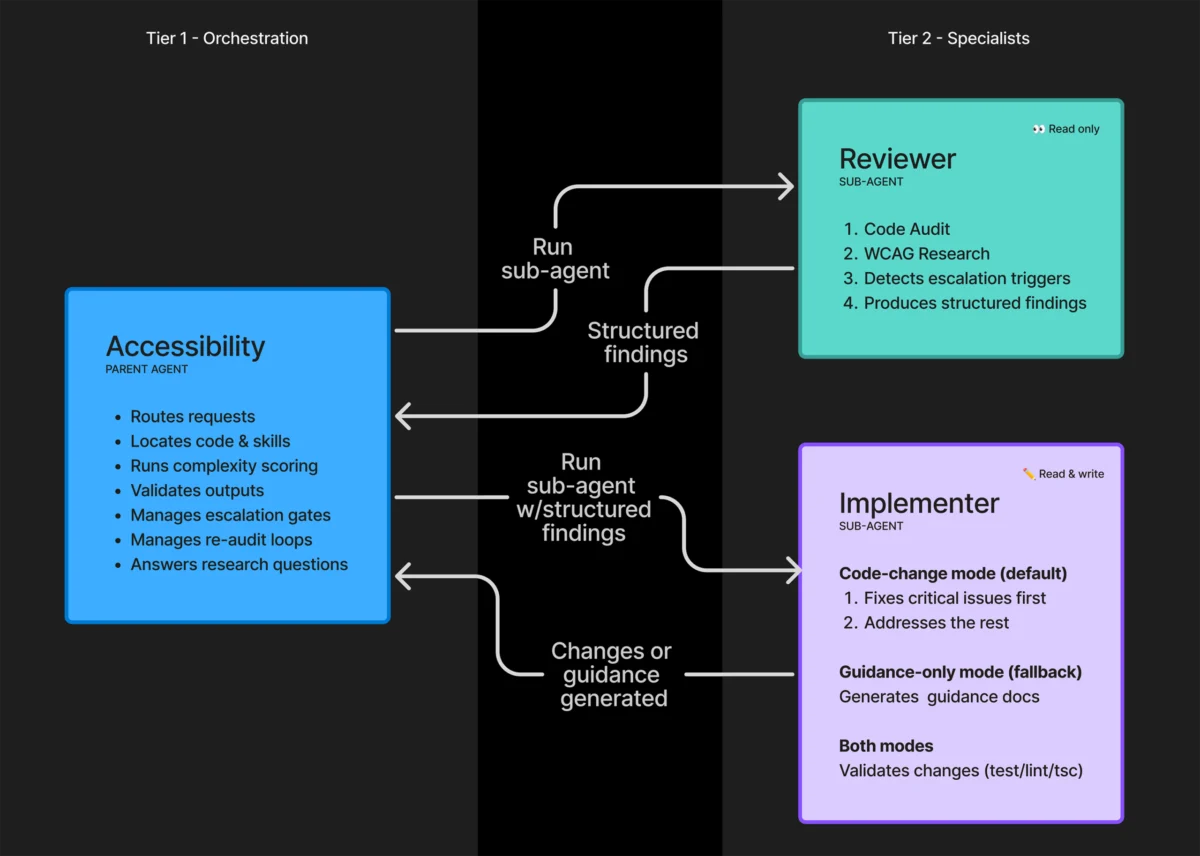
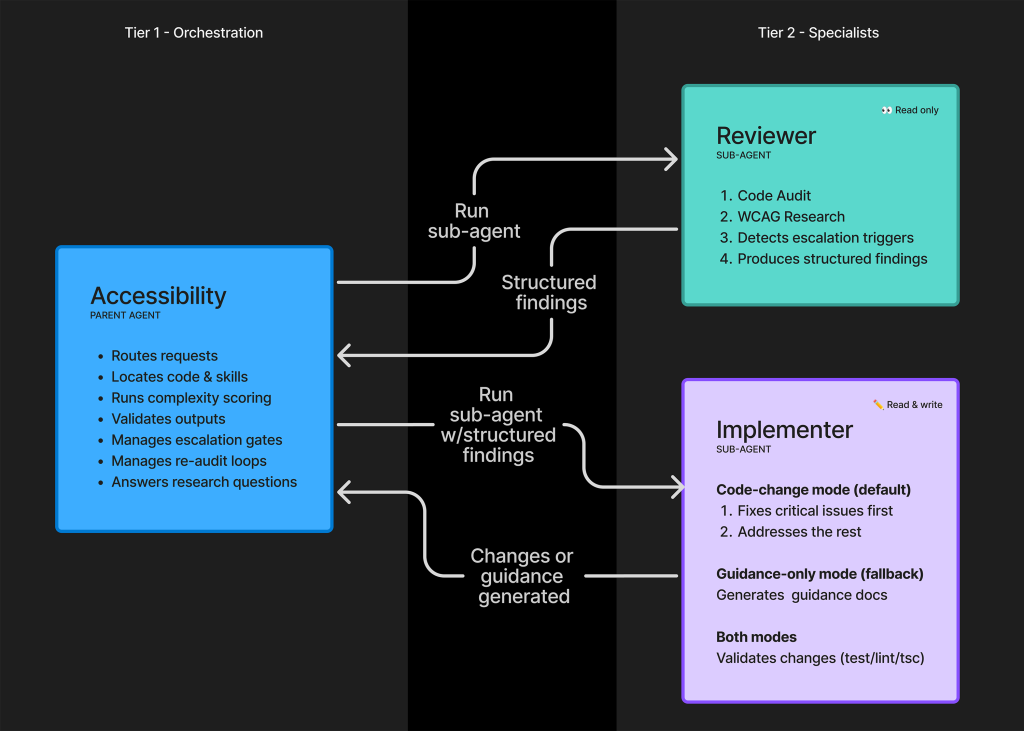
At its core, GitHub’s accessibility agent is designed to serve two primary functions: providing real-time guidance to developers and performing automated remediation on front-end code. Unlike traditional static analysis tools that often flag issues without providing context, this agent functions as a collaborative partner, analyzing code within the context of the user’s specific architectural decisions.
The agent is not an attempt to "solve" accessibility in a vacuum. Instead, it is built to augment the human-centric work of accessibility engineers. By operating as a specialized assistant, it identifies potential friction points for users of assistive technologies—such as screen readers or keyboard navigation tools—before they are merged into the codebase.
Chronology: From Concept to Deployment
The project emerged from GitHub’s long-standing commitment to the "disability divide" in tech. Recognizing that the social model of disability dictates that environments create barriers, the team sought to address the digital environment of GitHub itself.
- Foundation: The team began by leveraging a mature, existing system of logging accessibility issues. By centralizing these issues into a single repository, GitHub created a "gold mine" of structured, contextual data. This historical data allowed the LLM to learn from real-world fixes rather than just generic documentation.
- Implementation: Initial tests involved a monolithic agent structure. However, the complexity of accessibility—which touches design, copywriting, and technical implementation—quickly overwhelmed a single-agent architecture.
- Refinement: The team shifted to a "sub-agent" architecture, separating the "reviewer" (read-only, diagnostic) from the "implementer" (write-capable, remediating). This transition was critical in managing token consumption and ensuring the accuracy of the outputs.
- Current Status: The agent is currently in a pilot phase, having reviewed over 3,500 pull requests with a 68% resolution rate, proving that AI-led accessibility intervention is not just theoretical, but highly practical.
Supporting Data: Efficiency and Precision
The metrics behind the pilot suggest a high degree of efficacy. By focusing on the most common friction points—such as meaningful sequence errors, missing labels, and incorrect DOM ordering—the agent has successfully streamlined the developer experience.
Token Consumption and Architectural Efficiency
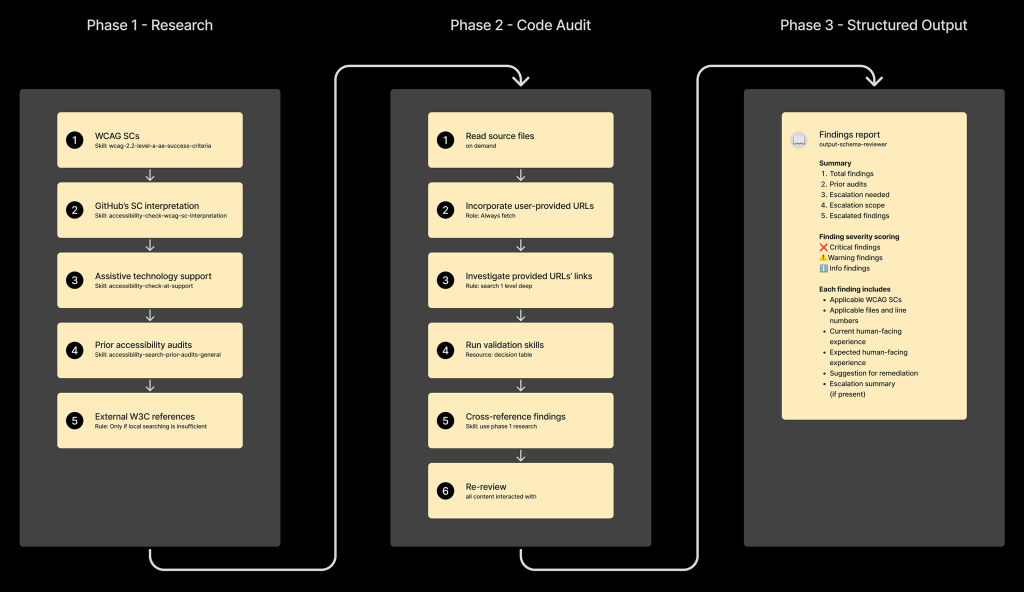
One of the primary challenges in deploying LLM agents for accessibility is the "token tax." Accessibility is highly contextual, requiring the agent to understand the full scope of a UI component. To combat excessive token usage and the risk of "hallucinated" code, GitHub implemented:
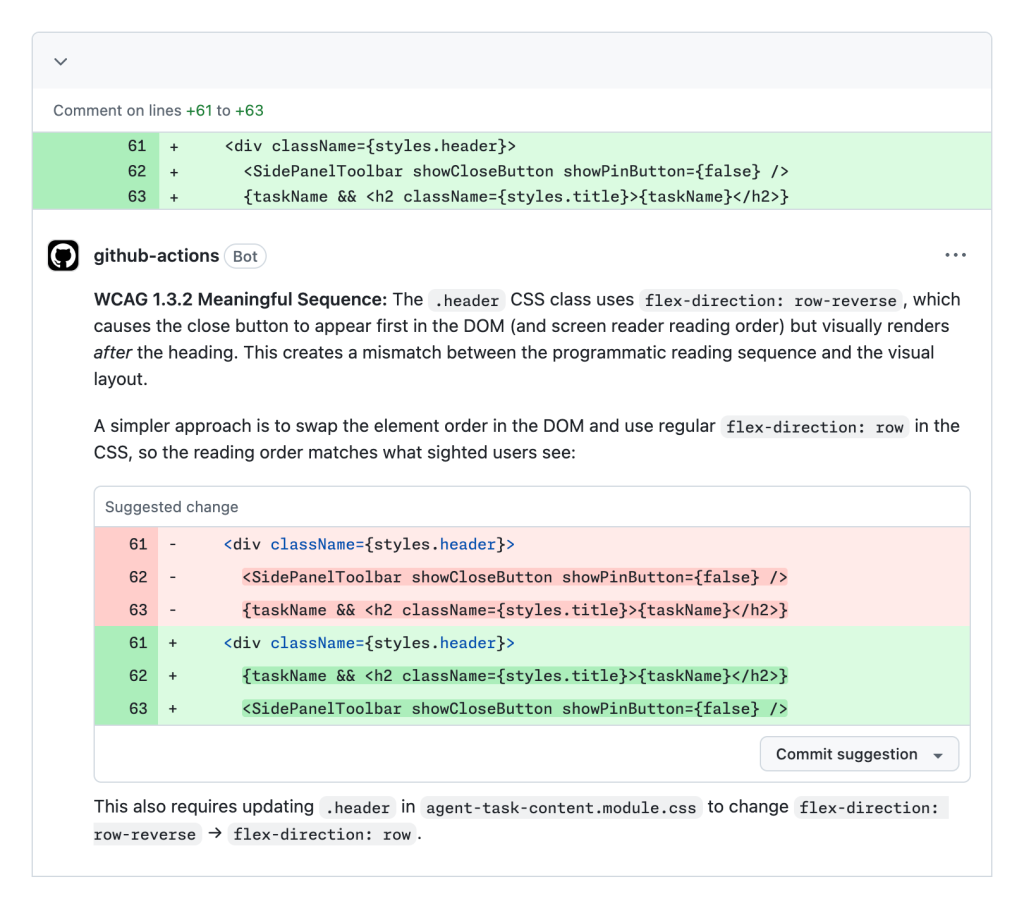
- Linear Order Execution: The agent follows a strict, step-by-step auditing process that mimics a human auditor’s workflow (Research -> Code Audit -> Reporting).
- Template Schemas: By forcing sub-agents to communicate through predefined schema templates, the team minimized redundant communication and ensured that the "reviewer" and "implementer" modules remained focused.
- Complexity Thresholds: A shell script analyzes code complexity before the agent is triggered. If a UI pattern is deemed too complex or high-risk—such as data grids or rich text editors—the agent defaults to a "consultation required" mode rather than attempting an automated fix.
Official Responses and Strategic Mindset
The philosophy driving this project is clear: avoid the "silver bullet" trap. The team acknowledges that LLMs are frequently biased toward producing accessibility antipatterns because they are trained on decades of inaccessible legacy code.
"We are not attempting to solve accessibility in isolation," the team notes. By establishing clear "escalation gates," the agent knows when to stop generating code and request a human review. This is crucial for compliance with upcoming global regulations, such as the European Accessibility Act and the impending 2027 enforcement of WCAG 2.1 AA standards under the Americans with Disabilities Act.
Organizations that fail to invest in the manual identification and remediation of accessibility issues now will find themselves at a severe disadvantage. The GitHub pilot demonstrates that the most successful AI agents are those built on a foundation of high-quality, human-curated datasets.
The Limits of Automation
Despite the success of the pilot, the project team is transparent about the limitations of AI.
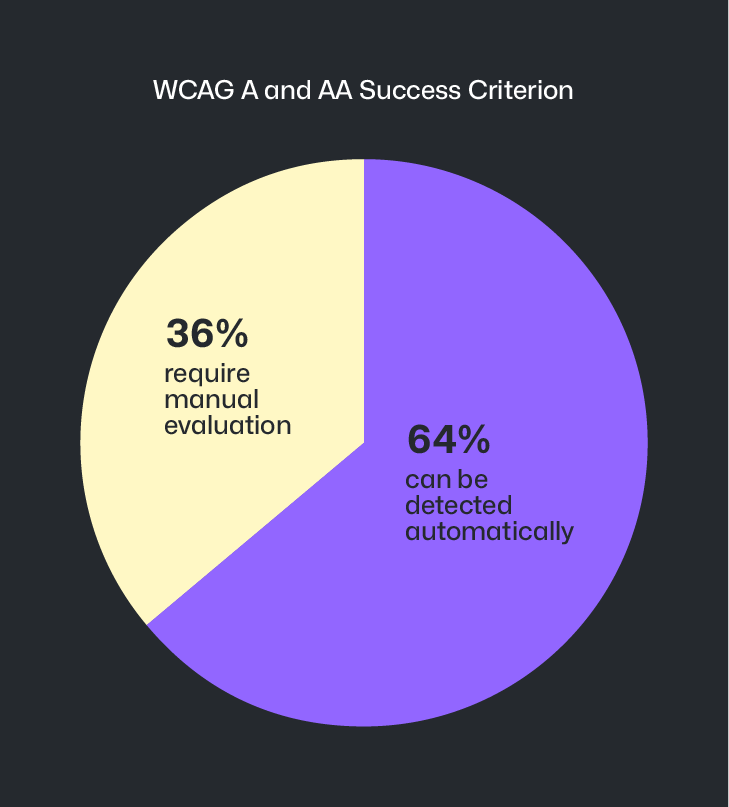
The 36% Gap
The most critical takeaway is that automated tools are not exhaustive. While approximately 64% of WCAG Level A and AA success criteria can be detected by machines, roughly 36% require manual, human evaluation. This means that no matter how sophisticated the agent becomes, it can never replace the need for early-stage design accessibility and user testing.
High-Risk Patterns
The agent is explicitly programmed to avoid "high-risk" UI patterns. These include:
- Drag-and-drop interfaces: Often functionally inaccessible if not implemented with specific focus management.
- Rich text editors: Highly complex components that require specialized accessibility trees.
- Tree views and Data Grids: Patterns where keyboard navigation logic is notoriously difficult to standardize.
By preventing the agent from "guessing" the solution for these patterns, the team avoids the reputational and technical risks associated with providing incorrect accessibility guidance.
Implications for the Future of Development
The broader implication of GitHub’s experiment is the potential for open-sourcing these accessibility workflows. As part of their pledge to improve the accessibility of open-source software at scale, GitHub aims to share these methodologies with the wider developer community.
The success of this agent suggests a future where accessibility is a default, "shift-left" activity. Rather than accessibility being a final checkbox before deployment, it is becoming an automated, iterative process that guides developers in real-time.
Key Lessons for Other Teams:
- Invest in Data: Use your existing issue trackers to build a library of "gold" examples. The LLM will perform best when it is grounded in your organization’s specific conventions.
- Use Sub-Agents: Don’t build a monolith. Segmenting your agent into specialized roles (researcher vs. implementer) creates safer, more predictable outputs.
- Implement Guardrails: Build "anti-gaming" instructions to prevent the agent from overriding its own safety protocols.
- Accept Human Necessity: Automate the "easy" wins to free up your human experts to focus on the 36% of accessibility issues that remain beyond the reach of current AI.
As GitHub continues to iterate on this technology, the goal remains clear: to ensure that the platform—and by extension, the software built upon it—is accessible to all. The agent is not just a tool; it is a signal that the era of "accessibility as an afterthought" is rapidly coming to an end. By learning in the open, GitHub is providing a roadmap for the rest of the industry to follow, turning the complex challenge of digital inclusion into a scalable, automated reality.








