In the high-stakes world of social media, where billions of users scroll through an endless feed of content, the ability to serve the "right" item at the right time is the lifeblood of the platform. For years, the industry has relied on a "microservice mesh"—a collection of specialized, standalone services stitched together to filter millions of possibilities down to a personalized selection. But as recommendation models have grown in sophistication, this architecture has hit a structural ceiling.
Meta has now unveiled SilverTorch, a radical reimagining of this retrieval ecosystem. By collapsing complex, fragmented microservices into a single, unified neural network, SilverTorch introduces a new paradigm known as "Index as Model." This shift not only shatters existing latency barriers but also promises a new era of compute efficiency and recommendation quality.
Main Facts: The "Index as Model" Paradigm
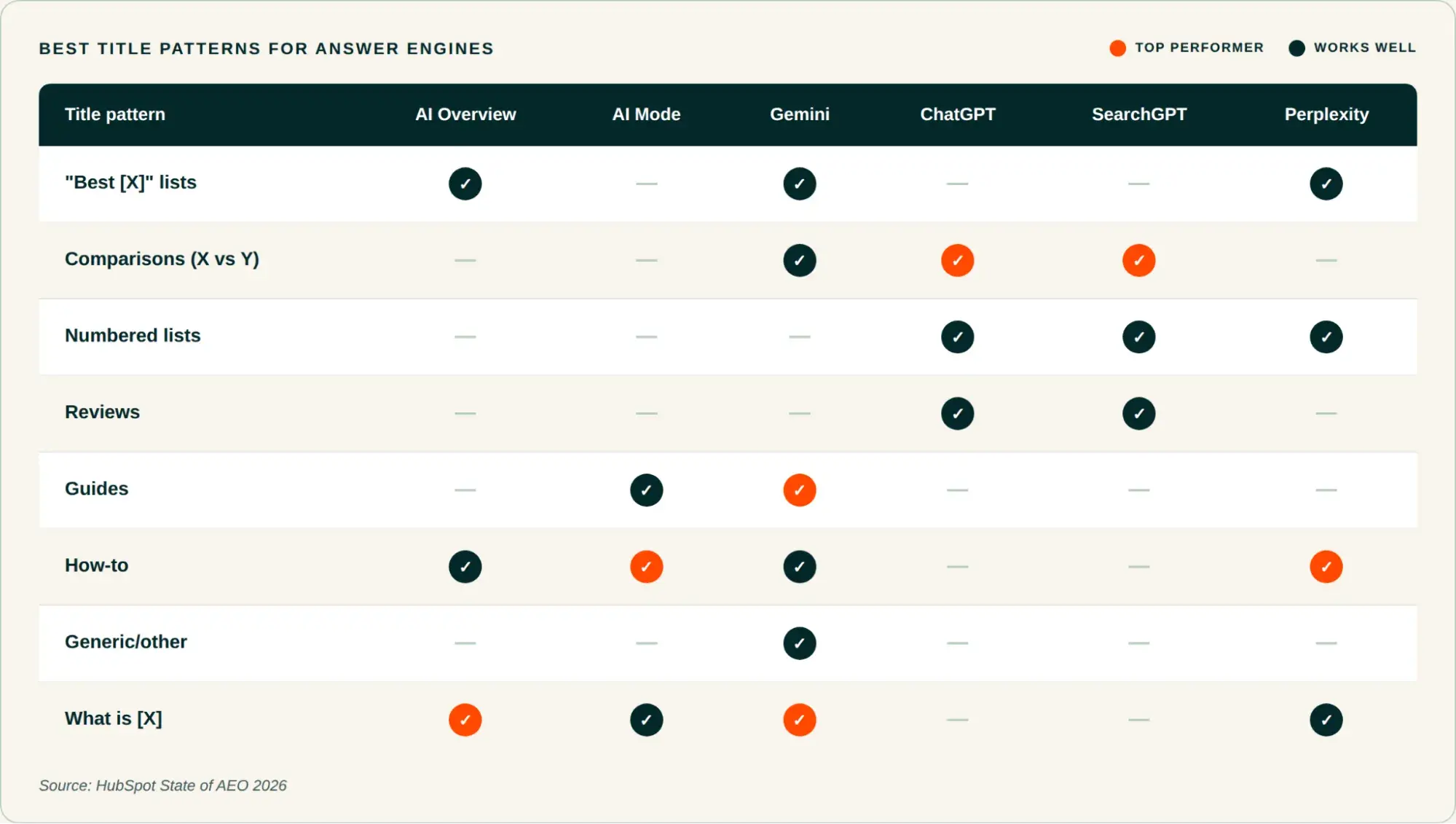
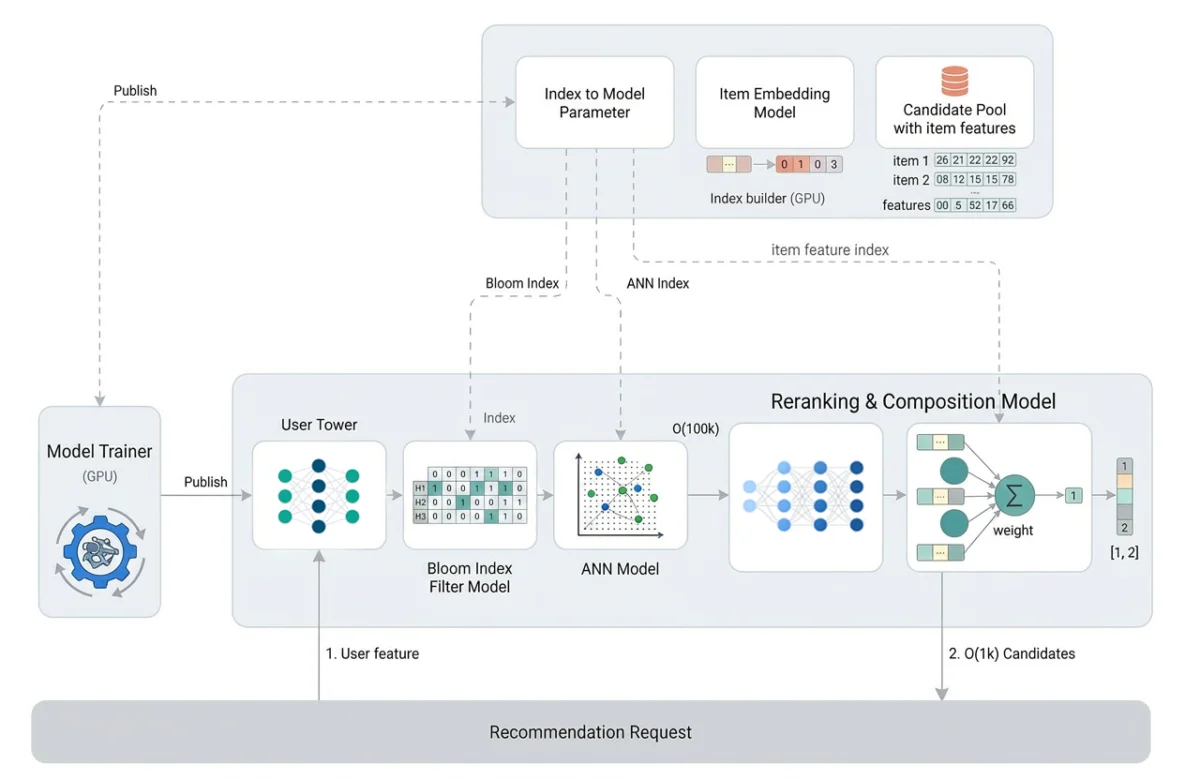
At its core, SilverTorch replaces the traditional, multi-service retrieval pipeline with a single, integrated PyTorch model. In legacy systems, retrieval was a fragmented journey: an orchestrator would call a user-tower service, then an index search service, then an eligibility filter, and finally a scoring service. Each component operated in its own silo, often written in different languages with distinct deployment cycles.
SilverTorch changes this by treating every component—the item index, eligibility filters, and scoring layers—as a tensor or operator within a single PyTorch graph. When a user opens their app, a single request flows through the SilverTorch model. This model performs approximate nearest neighbor (ANN) search, filters for policy compliance, and executes multi-task reranking in one cohesive forward pass.
By moving these functions into the model graph, the system eliminates the overhead of network hops and data serialization. This allows for significantly higher modeling complexity and a vastly larger candidate pool, all while maintaining the strict sub-100 millisecond latency requirements critical for a seamless user experience.
A Chronological Evolution: From CPU-Era Mesh to GPU-Native Intelligence
The Limitations of the Microservice Mesh
Traditional recommendation systems were born in the CPU era. They were built for modularity, allowing teams to swap out an ANN search library or an eligibility filter independently. However, as the scale of social platforms exploded, this design became a liability. The "hand-off" between services created artifacts, restricted cross-module optimization, and led to severe inefficiencies.
The Shift to Pure PyTorch
Meta’s engineering team realized that component-level optimizations—such as faster CPU-based libraries—were reaching diminishing returns. The solution was a fundamental architectural shift: "Index as Model." The transition occurred in three distinct stages:
- Reproduction: The team ported every legacy retrieval module (ANN, filtering, ranking) into pure PyTorch. This allowed the system to leverage GPU memory and unified execution paths.
- Rethinking: The team abandoned "porting" in favor of redesigning. They built GPU-native primitives like the Bloom index filter and fused Int8 ANN search, which are optimized for the massive parallelism of modern GPU hardware.
- Co-design: Finally, the team enabled backpropagation for these modules. This allowed the entire retrieval pipeline to be trained jointly, ensuring that every part of the funnel is optimized to feed the next.
Supporting Data: Efficiency and Performance Metrics
The performance gains achieved by SilverTorch are not merely incremental; they are transformative. When compared to legacy FAISS-CPU and FAISS-GPU implementations on a production workload of 80 million items, SilverTorch demonstrated clear superiority.
| Metric | FAISS-CPU | FAISS-GPU | SilverTorch |
|---|---|---|---|
| Compute Efficiency | Baseline | 5.9x | 20.9x |
| Max Top-K | Limited | 2,048 | 100s of thousands |
| Neural Reranking | No | No | Yes |
| Multi-task Scoring | No | No | Yes |
The efficiency gains—nearly 14x faster even with reranking included—are driven by several technical breakthroughs:

- Fused Int8 ANN Kernel: By storing item embeddings in compact Int8 format, the system cuts memory usage in half, allowing for more candidates to be stored in high-bandwidth memory (HBM).
- Bloom Index Filtering: By using bit operations to verify eligibility, the system bypasses the load-balancing issues that plague traditional inverted indices on GPUs.
- Reduced Data Movement: Because the entire pipeline resides in GPU memory, the system eliminates the constant movement of data between host DRAM and GPU VRAM.
Official Responses and Strategic Implications
Meta’s engineers emphasize that SilverTorch is not just an infrastructure project; it is a democratizing force for recommendation modeling. By dissolving the boundary between infrastructure engineering and machine learning engineering, the system allows researchers to test complex ideas in days rather than weeks.
"Full model-based retrieval is viable and efficient at production scale," the engineering team noted in their official release. "The architecture breaks down the wall between infrastructure and modeling, and they become one unified practice."
The implications for the user experience are profound. Because SilverTorch can handle orders of magnitude more candidates than previous systems, it can apply sophisticated, multi-task scoring layers to a wider funnel. This means users receive content that is not only relevant to their immediate interests but also filtered through a nuanced understanding of their engagement habits (likes, shares, comments) at the earliest stage of the pipeline.
Furthermore, the system’s "streaming update" mechanism ensures that the model remains fresh. Rather than requiring a full model redeployment, the system performs targeted, in-place updates to specific tensors, allowing the platform to surface same-day, trending content with unprecedented speed.
Future Outlook: The Role of LLMs
The evolution of SilverTorch does not stop at traditional recommendation. As the industry pivots toward Large Language Models (LLMs) for understanding content semantics and user intent, SilverTorch provides the ideal "home" for these technologies.
Instead of orchestrating LLMs as a separate, latency-heavy service, Meta plans to integrate LLM capabilities directly into the retrieval model. This "tighter coupling" means that the semantic intelligence of an LLM can be used to prune the candidate pool, ensuring that only the most contextually relevant content ever reaches the final ranking stage.
Conclusion
By treating the recommendation index as a living, breathing neural network rather than a static database of pointers, SilverTorch has successfully bridged the gap between raw compute power and human-level content curation. As the system continues to roll out across Meta’s apps—from Instagram to Threads—it sets a new standard for what is possible in large-scale AI.
The success of SilverTorch serves as a blueprint for the next generation of recommendation systems: move the intelligence to the data, integrate the pipeline into a single graph, and let the model do the heavy lifting. For further technical details, the full research paper, "SilverTorch: A Unified Model-based System to Democratize Large-Scale Recommendation on GPUs," is available through the SIGIR 2026 proceedings.