
In the modern software ecosystem, few tasks are as universally dreaded by engineers as large-scale library or dataset migrations. The process is a familiar cycle of manual toil: identifying affected repositories, writing boilerplate code, navigating inconsistent internal frameworks, and hunting down downstream teams to ensure compatibility. At Spotify, this cycle was recently disrupted by "Honk," an internal background coding agent designed to handle the heavy lifting of software maintenance.
This case study, the fourth in a series detailing Spotify’s journey with autonomous agents, explores how a single team leveraged Honk, integrated with the Backstage developer portal and Fleet Management platform, to migrate thousands of dataset consumers. The result? A massive reduction in manual labor—saving an estimated 10 engineering weeks—and a blueprint for the future of autonomous software maintenance.
The Chronic Pain of Data Migration
At the end of 2024, a pivotal data engineering team at Spotify faced a daunting mandate: deprecate two of the company’s most heavily utilized datasets. These datasets were the foundation for thousands of downstream pipelines. To introduce new dimensions and unlock advanced analytical features, these legacy endpoints had to be retired.
The scope was staggering: approximately 1,800 direct downstream data pipelines across three distinct frameworks—SQL-based BigQuery Runner, dbt, and the Scala-based Scio. Because these pipelines touched nearly every corner of the organization, the indirect impact spanned several thousand additional data processes.
For human engineers, this represented a logistical nightmare. Calculating the timeline, the team estimated that performing these migrations manually—even with high levels of coordination—would consume roughly 10 weeks of dedicated engineering effort. Faced with this bottleneck, the team turned to Honk, Spotify’s autonomous coding agent, to see if the complexity could be tamed through automation.
Chronology: A Multi-Stage Automation Strategy
Phase I: Lineage Discovery via Backstage
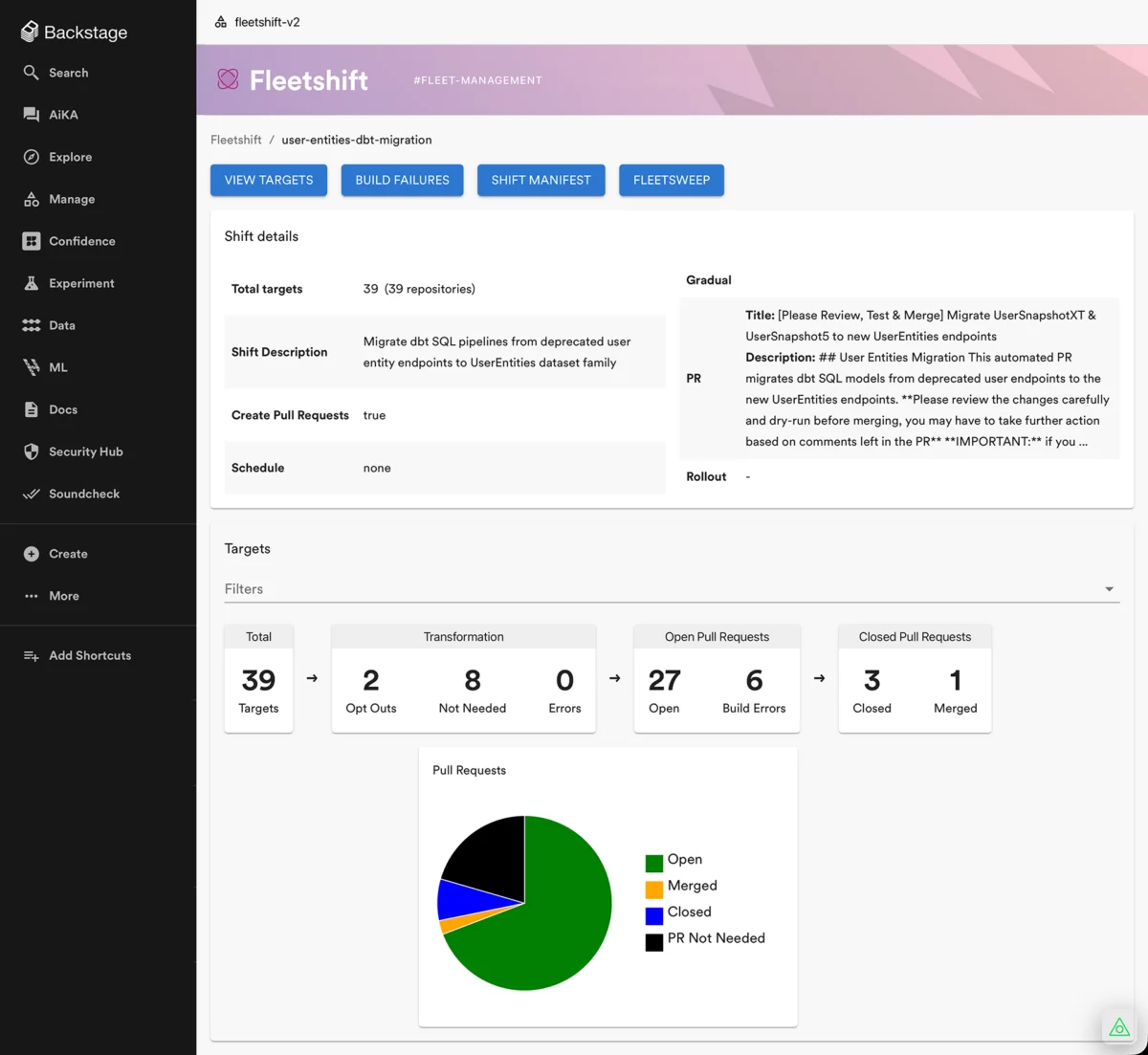
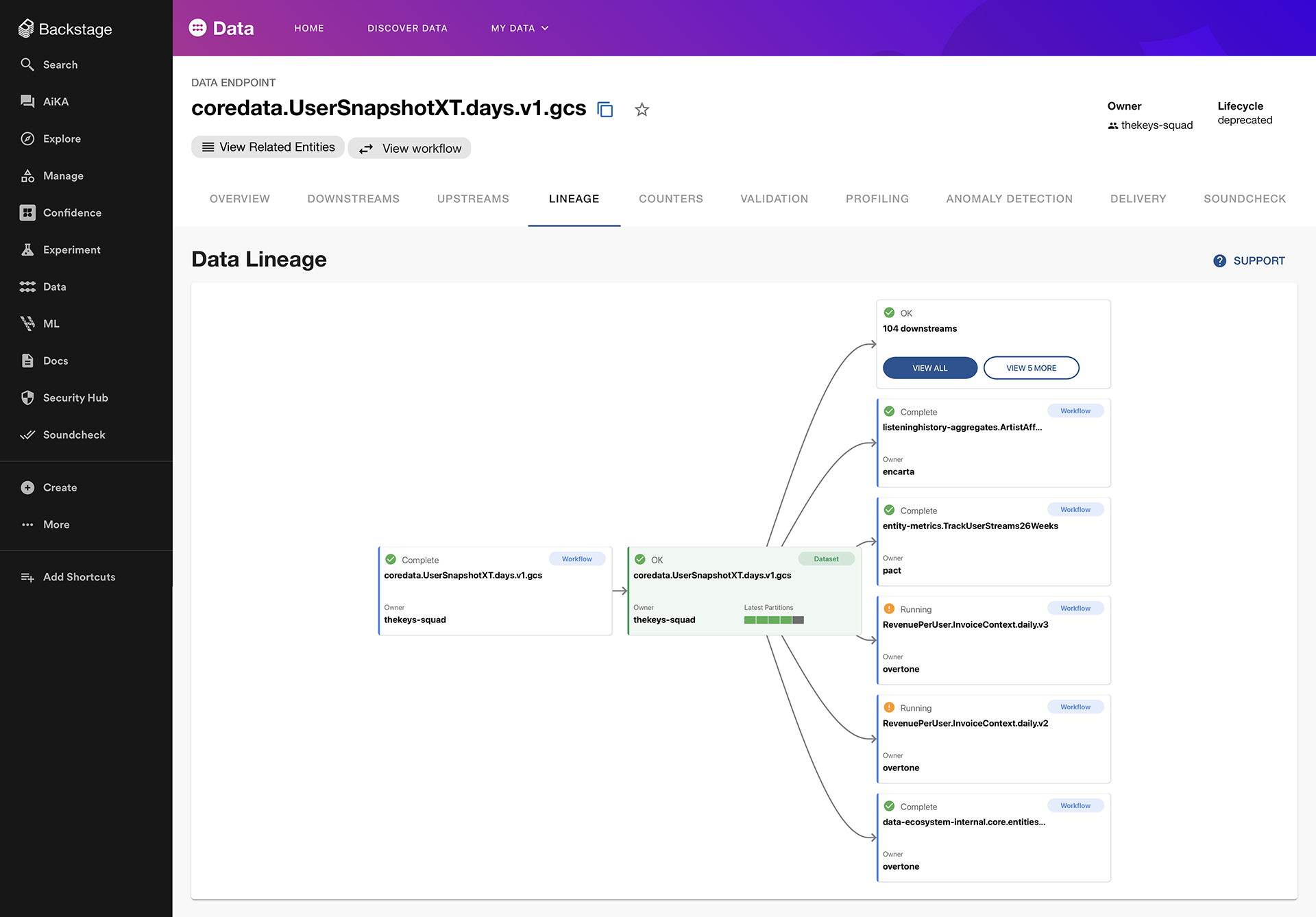
Before a single line of code could be rewritten, the team needed total visibility. Using the Backstage developer portal, the team utilized endpoint lineage and Codesearch plugins. By mapping the dependencies of the deprecated datasets, they identified precisely which repositories required updates. This wasn’t just a list; it was an orchestration map. The team marked these repositories as "in-scope" and utilized the Fleetshift plugin to manage the migration workflow, turning a chaotic discovery process into a structured, visible project.
Phase II: The Context Engineering Challenge
As detailed in previous installments of this series, "context engineering" is the lifeblood of background coding agents. Honk does not possess innate knowledge of Spotify’s proprietary quirks; it relies entirely on the context provided to it.

The team hit their first significant hurdle here: framework inconsistency. While dbt and BigQuery Runner followed predictable, standardized patterns, Scio pipelines varied wildly depending on the team that wrote them. Attempting to write a universal prompt that could account for the flexibility of Scio proved futile at the time. Consequently, the team made the pragmatic decision to automate the standardized frameworks first, setting aside Scio for manual handling to ensure accuracy.
Phase III: Iterative Prompt Refinement
The initial attempts to feed Honk a human-written migration guide resulted in "hallucinations"—the agent made incorrect assumptions about how to map old dataset fields to new ones. The breakthrough occurred when the team moved away from narrative instructions and toward structured data. By providing explicit mapping tables within the context files, the team constrained Honk’s decision-making process. They also implemented "guardrails": for complex, judgment-heavy logic, Honk was instructed to leave the code untouched and instead insert comments linking to human-readable migration guides. This effectively turned the agent into a force multiplier rather than a replacement for human oversight.
Phase IV: Execution and Monitoring
Using Fleetshift, the team pushed 240 automated pull requests (PRs) across the company. The Fleetshift UI provided a real-time dashboard, allowing the team to monitor the progress of each migration and communicate directly with the owning teams. By treating the PRs as transparent, automated suggestions, the team successfully navigated the rollout without breaking the underlying data infrastructure.
Supporting Data and Technical Realities
The efficacy of Honk is best understood through the constraints the team faced during the migration.
- Standardization as a Pre-requisite: The success rate was significantly higher in repositories that followed standard Spotify architecture (dbt and BigQuery Runner). In environments where standardization was lacking, the agent struggled to generate reliable code.
- The Verification Gap: A critical limitation noted during this project was the lack of build-time unit testing in many data repositories. Because Honk could not run its own "verification loops" (a feature of its more advanced iterations), it could not self-validate its changes. This meant that the final verification—the actual testing of the data migration—still required human intervention from the downstream teams.
- Engineering Efficiency: By automating the repetitive task of field-mapping and repository updates, the team bypassed approximately 10 weeks of labor.
Official Perspectives: The Path to Autonomy
In discussing the project, the engineering leadership at Spotify emphasized that this was as much a lesson in organizational structure as it was in AI.
"The success of our background coding agents is inextricably linked to the state of our codebase," one lead engineer noted. "If we want agents to work autonomously, we must move toward a more standardized data landscape. When code is idiosyncratic, agents struggle. When code is modular and tested, agents thrive."
The team is now looking toward the next evolution of Honk. The current roadmap includes "agentic agency," where Honk will be equipped to read JIRA tickets, technical documentation, and external schemas independently before initiating changes. By moving away from static, pre-written context files, the agent will become more adaptive, capable of handling the nuances of Scio and other flexible frameworks that previously proved too difficult to automate.
Implications for the Future of Software Maintenance
The implications of this experiment are profound for large-scale software engineering.
1. From "Manual Toil" to "Policy Enforcement"
The migration project suggests that the future role of the "Lead Engineer" in a large organization will shift from performing migrations to designing the policy that the agent executes. By defining the rules of the migration, engineers can offload the execution to agents, freeing them to focus on high-level system architecture and strategy.
2. The Feedback Loop Necessity
The project highlighted that agents are only as good as the feedback loops they inhabit. Without unit tests, an agent is effectively "flying blind." As a result, Spotify is now prioritizing the enforcement of testing standards as a prerequisite for agent-assisted maintenance. In essence, the requirement for machine-readable code is forcing the organization to improve its overall software quality.
3. Scaling the Human-AI Collaboration
The use of Fleetshift to manage these migrations proves that "agentic workflows" need a central nervous system. A single agent might rewrite one file, but an orchestrator like Fleetshift can manage a thousand repositories simultaneously. This creates a new operational layer: human operators managing an "agent fleet" to ensure compliance and consistency across the enterprise.
Conclusion
Spotify’s migration of its dataset consumers is a landmark case in the history of autonomous coding agents. It demonstrates that while agents like Honk are not yet "silver bullets" that can replace human engineers, they are powerful, force-multiplying tools that can eliminate the most tedious aspects of software maintenance.
As the technology matures, the combination of Backstage’s orchestration, Fleetshift’s visibility, and Honk’s coding capabilities will likely become the standard operating procedure for every major technical migration at Spotify. For the engineering community at large, the message is clear: the path to a more autonomous future begins with standardizing your architecture today, so your agents can build your future tomorrow.








