
In the modern operations department of a medium-sized enterprise, the workday is often defined by the "PDF bottleneck." Every morning, teams are flooded with incoming B2B purchase orders. On the surface, these documents are identical: they all contain a Customer ID, a Purchase Order (PO) number, a delivery date, and a list of ordered items. Yet, in practice, no two documents are the same.
One customer places the PO number in the top-left corner; another buries it in the bottom-right. Some label it "PO Number," while others use "Order ID," "Order Reference," or even more obscure internal nomenclature. For a human operator, this is a trivial cognitive task—we look at the page, understand the context, and instantly identify the relevant data. For traditional automation systems, however, this diversity of layout represents a catastrophic failure point.

This article examines the ongoing shift in document processing: the transition from brittle, rule-based extraction to semantic, Large Language Model (LLM)-driven pipelines. We explore when traditional systems reach their breaking point and how modern AI offers a path toward sustainable, scalable automation.
1. The Anatomy of the Bottleneck: Traditional Extraction
Traditional automation relies heavily on Optical Character Recognition (OCR) coupled with Regular Expressions (Regex). A Regex rule is essentially a "find and replace" logic on steroids. It looks for specific patterns, such as the text string "PO Number: " followed by a numeric sequence.

The Fragility of Regex
The fundamental flaw of Regex is its rigidity. If a programmer writes a rule to scan for "PO Number," the system will return a null value the moment it encounters "Order Reference." As a company grows, the number of unique vendor templates increases. If you have 200 customers, you effectively need to maintain 200 different sets of rules. When a single customer changes their document layout—a common occurrence—the pipeline breaks. This creates a "maintenance debt" that often consumes more engineering hours than the manual data entry would have required in the first place.
2. A Step-by-Step Guide: Comparing the Two Approaches
To understand the performance gap, we performed a head-to-head comparison between a traditional regex-based pipeline and a modern LLM-powered workflow using LLaMA 3.

The Setup: Mise en Place
Before beginning, we established a local Python environment using venv. We utilized Tesseract as our OCR engine to convert raw image scans of PDFs into machine-readable text. For PDF-to-image conversion, we employed Poppler, an open-source rendering library.
- OCR Engine (Tesseract): We installed Tesseract, ensuring the system path was correctly configured so that Python’s
pytesseractlibrary could bridge the gap between our code and the engine. - PDF Rendering (Poppler): We downloaded the latest Poppler binaries and added them to the Windows PATH to ensure the
pdf2imagelibrary could accurately translate multi-page PDFs into image files for processing. - LLM Integration (Ollama): We deployed Ollama locally to run the LLaMA 3 model. This allows for data privacy and security, as sensitive B2B documents never leave the local machine to hit a public cloud API.
Execution
We generated two distinct test PDFs: Layout A (the standard format) and Layout B (a non-standard, "noisy" format).

- Approach 1 (Regex): We scripted a series of specific string-matching rules.
- Approach 2 (LLM): We fed the OCR-extracted text into LLaMA 3 with a prompt asking the model to parse the information into a JSON object based on semantic meaning rather than specific location.
3. The Results: Why Context Beats Rules
The results of our test were stark.
Approach 1 (Traditional): The system handled Layout A with perfect accuracy. However, when presented with Layout B, the system failed to extract any data. Because the labels were different and the structure had shifted, the regex rules could not find the expected anchors. The output was a string of "None" values.

Approach 2 (LLM-Driven): The LLM-powered pipeline correctly identified the data in both layouts. Because the LLM understands that "Order Reference" is semantically equivalent to "PO Number," it extracted the correct value without requiring a single new line of code or a custom rule for the second client. Furthermore, the LLM performed "normalization"—automatically converting disparate date formats (e.g., "DD/MM/YYYY" vs. "YYYY-MM-DD") into a unified standard.
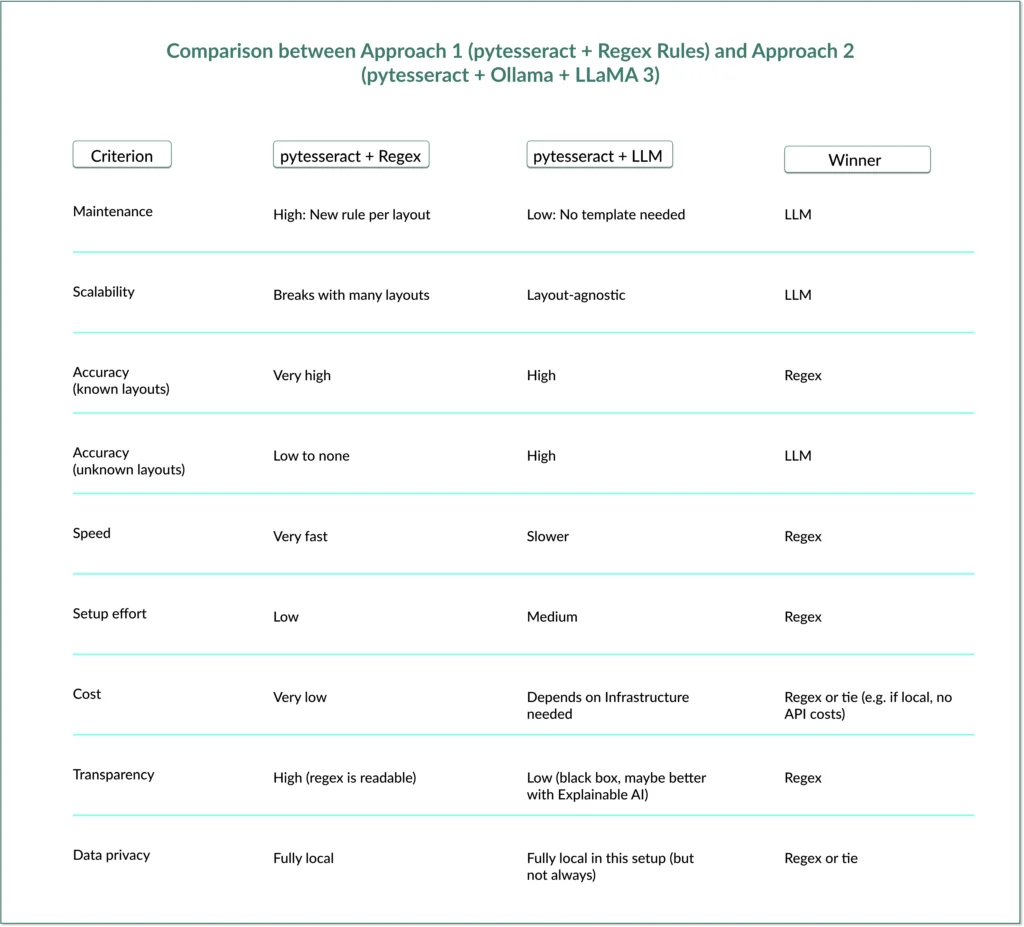
4. Supporting Data: The Trade-off Matrix
The following table outlines the strategic trade-offs observed during our implementation:

| Feature | Regex-Based Pipeline | LLM-Based Pipeline |
|---|---|---|
| Maintenance | High (Rule-per-template) | Low (Self-adjusting) |
| Accuracy | 100% (on known layouts) | 95-99% (probabilistic) |
| Inference Time | Milliseconds | Seconds |
| Infrastructure | Minimal | Requires GPU/RAM (Ollama) |
| Logic | Explicit | Semantic |
5. When Should You Avoid an LLM?
Despite the power of AI, it is not a panacea. There are critical scenarios where traditional methods remain superior:
- High-Volume, Stable Layouts: If you process thousands of documents from only three or four sources that never change, a regex-based approach is faster, cheaper to run, and easier to debug.
- Strict Regulatory Environments: In some industries, the "black box" nature of LLMs may be a compliance concern. Regex is deterministic—you can trace exactly why a value was extracted.
- Low-Resource Infrastructure: If your operations run on legacy hardware without GPU capabilities, the compute cost of running local LLMs might be prohibitive compared to simple script execution.
- Critical Accuracy Requirements: If a 1% error rate in data extraction could lead to massive financial losses, traditional systems—where you can enforce hard logic—are often preferred.
6. Strategic Implications
The shift toward LLM-based extraction is fundamentally a shift from coding for exceptions to designing for intent.

For the operations team, this represents a major change in the "automation mindset." Instead of spending 80% of their time updating regex rules to account for new vendor layouts, engineers can focus on building high-level validation logic. If an LLM extracts a price that looks suspicious, the system can flag it for human review. This is known as "Human-in-the-Loop" (HITL) architecture, which combines the speed of AI with the oversight of human expertise.
Is Your Company Ready for AI?
Implementing an LLM-based document parser is an ideal entry-level project for companies looking to modernize. It provides immediate, tangible value: reduced manual labor and faster order turnaround times. More importantly, it forces the IT department to build the infrastructure necessary for broader AI adoption, such as managing local model registries and prompt engineering best practices.

7. Final Thoughts: The Path Forward
The "Automation Paradox" is this: the more you try to automate using rigid rules, the more rigid your system becomes. By contrast, LLMs offer a way to embrace the inherent messiness of human communication.
While the traditional approach is not "dead," it is increasingly confined to niche, high-stability environments. For the vast majority of medium-sized businesses, the future lies in hybrid architectures—systems that use classic OCR for text capture and LLMs for the semantic heavy lifting.

By offloading the "understanding" of documents to an AI, organizations can reclaim their most valuable asset: the time of their employees. The goal of automation should not be to make the computer act like a machine, but to allow it to process information with the same flexibility and context as the humans who previously performed the work.
Where to Continue Learning
- Official Documentation: Visit Ollama.com to explore model quantization and deployment.
- Advanced Extraction: Research LangChain for building complex data extraction chains that combine multiple LLM steps.
- Evaluation Metrics: Explore RAGAS to learn how to quantify the accuracy of your extraction pipelines.
- GitHub Resources: Access the full code implementation of the comparison discussed here at this repository.
For more insights into the intersection of Data Science and operational efficiency, subscribe to the "Data Science Espresso" newsletter for weekly updates on AI tooling and Python best practices.








