
For developers building Retrieval-Augmented Generation (RAG) pipelines, the frustration is all too familiar. You spend weeks curating high-quality data, fine-tuning your embedding model, and selecting a state-of-the-art Large Language Model (LLM). Yet, when you deploy the system, the answers are frequently vague, incorrect, or—worst of all—confidently hallucinated.
In the vast majority of these cases, the failure lies not in the LLM’s reasoning capabilities, but in the "under-appreciated craft" of chunking. If you feed an LLM fragmented, context-deprived snippets of your knowledge base, you are essentially asking a world-class scholar to solve a complex puzzle with half the pieces missing. This article explores the evolution of RAG architectures and provides a definitive framework for navigating the critical intersection of data preparation and retrieval.
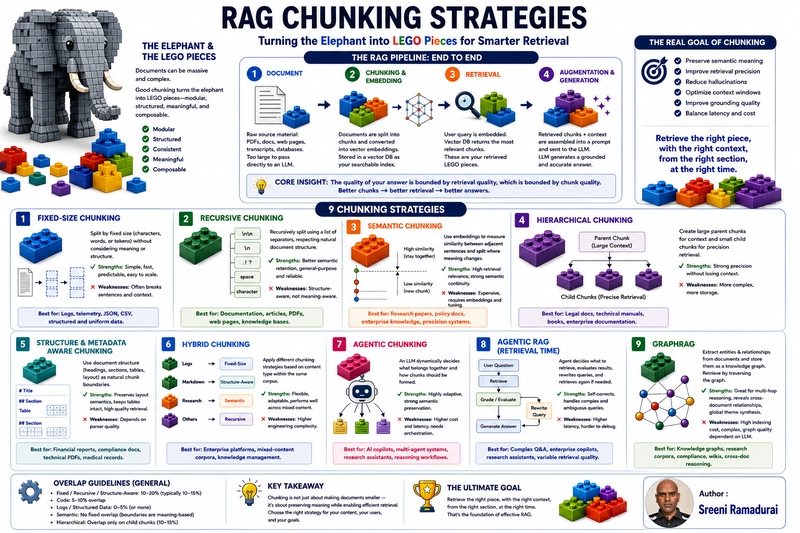
The Elephant and the LEGO Bricks: A New Mental Model
Think of your enterprise knowledge base—comprised of thousands of pages of legal contracts, dense technical manuals, and years of internal communications—as an "elephant." It is massive, complex, and deeply interconnected. An LLM cannot consume this entire "elephant" at once due to context window constraints, processing costs, and the noise that comes with feeding raw, unrefined data into a model.
To make this data useful, we must break the elephant into smaller pieces. However, this is where most RAG systems fail. If you chop your data into random, uniform segments, you destroy the semantic integrity of the information. Relationships vanish, sentences are cut in half, and the "meaning" of the text is lost.

Instead of thinking about "splitting" documents, we must think about turning the elephant into "LEGO pieces." A well-designed chunk should be a self-contained unit that preserves the structure, semantic intent, and contextual relationships of the original text, while remaining small enough for efficient vector retrieval. The goal of sophisticated chunking is simple but ambitious: to ensure that when a user asks a question, the retrieval system returns the exact pieces required to construct a grounded, accurate, and contextually rich response.
The RAG Pipeline: A Chronology of Data Flow
Every robust RAG architecture, regardless of its underlying complexity, follows a four-stage lifecycle. Understanding this flow is essential for diagnosing where your system might be breaking down.
- Stage 1: Document Ingestion: This is the raw data phase. Whether you are dealing with PDFs, web scrapes, or database exports, the data is currently too bloated for an LLM.
- Stage 2: Chunking and Embedding: The "pre-processing" phase. Here, documents are parsed and converted into vector embeddings—numerical representations of semantic meaning. Your choice of chunking strategy at this stage dictates the precision of every downstream interaction.
- Stage 3: Retrieval: When a query is entered, it is also embedded. The vector database identifies the chunks with the highest similarity to the query. These are your retrieved LEGO pieces.
- Stage 4: Augmentation and Generation: The retrieved chunks are injected into a prompt, providing the LLM with the necessary "ground truth." The model then synthesizes this data into a final answer.
The core insight here is that the quality of the LLM’s output is strictly bounded by the quality of the retrieval, which is, in turn, bounded by the quality of the chunks.
Taxonomy of Chunking Strategies
1. Fixed-Size Chunking
The most basic approach, splitting by character or token count. While fast and scalable, it is often destructive, as it ignores sentence boundaries and document structure. It is best suited for uniform data like logs or telemetry.

2. Recursive Chunking
The "industry standard" for most general-purpose applications. It traverses a hierarchy of separators (paragraphs, sentences, words) to keep chunks within a size limit while respecting natural document flow.
3. Semantic Chunking
A more intelligent approach that measures the semantic similarity between adjacent sentences. When the similarity drops below a specific threshold, a new chunk begins. This ensures that every chunk represents a coherent topic.
4. Hierarchical Chunking
This strategy uses a "parent-child" relationship. Small child chunks are used for precise retrieval, while larger parent chunks provide the LLM with the necessary surrounding context. It effectively bridges the gap between precision and context.
5. Structure-Aware Chunking
For documents with heavy formatting (HTML, Markdown, PDFs), this strategy uses headers, titles, and table structures to delineate chunks. It ensures that a header remains attached to the content it describes, preserving the logical hierarchy of the document.

6. Hybrid Chunking
A strategy for complex enterprise environments where data is heterogeneous. It applies different chunking logic depending on the document type (e.g., Semantic for research papers, Recursive for documentation, and Fixed-size for logs).
7. Agentic Chunking
An emerging, advanced frontier where an LLM is used to interpret the text and dynamically determine where to split based on topical shifts. It is highly precise but computationally intensive.
Architectural Evolution: Beyond Basic RAG
Agentic RAG: The Adaptive Loop
Standard RAG is static and linear. Agentic RAG introduces "reasoning" into the pipeline. By using frameworks like LangGraph, the system can now treat retrieval as a stateful, iterative process. If an agent retrieves irrelevant chunks, it can "grade" them, rewrite the user’s query, and perform a second, more accurate retrieval. This self-correcting loop significantly reduces hallucinations.
GraphRAG: Connecting the Dots
While vector search is excellent for finding similar text, it often fails at multi-hop reasoning (e.g., "What is the relationship between Project X and the budget cuts announced in the 2022 report?"). GraphRAG, popularized by Microsoft, extracts entities and relationships into a knowledge graph. By traversing this graph, the system can uncover connections across disparate documents, providing a level of insight that simple vector similarity cannot touch.

Supporting Data and The "Core Trade-Off"
When deciding on a strategy, architects face the "Goldilocks" problem:
- Too Small: Chunks are precise but lack the surrounding context required for a comprehensive answer. This often leads to fragmented, incomplete responses.
- Too Large: Chunks contain too much noise, diluting the "signal" and making it harder for the embedding model to match the query accurately.
The following table summarizes the strategic trade-offs:
| Strategy | Complexity | Precision | Context Preservation |
|---|---|---|---|
| Fixed-Size | Low | Low | Poor |
| Recursive | Medium | Medium | Good |
| Semantic | High | High | Excellent |
| Hierarchical | High | High | Best |
Implications for Future Development
The maturation of RAG systems is shifting the focus from "which LLM should I use?" to "how can I best structure my data?"
For organizations, this has profound implications:

- Investment in Data Engineering: The "garbage in, garbage out" rule applies. Investing in high-quality document parsing and structural analysis is more valuable than spending on proprietary model fine-tuning.
- Modular Architectures: Future-proof systems are being built to be modular. A winning production architecture today typically combines Structure-Aware parsing with Hierarchical retrieval and an Agentic loop to ensure high-quality, self-correcting outputs.
- Evaluation is Key: Because there is no "one-size-fits-all" strategy, businesses must implement rigorous evaluation frameworks (such as RAGAS or TruLens) to measure retrieval relevance, faithfulness, and answer correctness against their specific corpus.
In conclusion, the era of "naïve RAG"—where a simple vector store and a recursive splitter sufficed—is coming to a close. The next generation of enterprise AI will be defined by systems that treat documents as structured, interconnected knowledge, using intelligent chunking to ensure that the LLM is always provided with the right information at the right time. The secret to success isn’t just in the model; it’s in the craftsmanship of the data that fuels it.








